- 인터넷은 우리에게 자유를 주었습니다. 저희는 자유를 얻기 위해 지식을 통합하고 체계화하고 공유합니다. 랜선 위 정글에서 살아남기 위해 저희는 시키는 일만 하는 꿀벌 대신 고객을 위해 창조하고 혁신하는 게릴라가 되겠습니다. Seenbuy.kr is now Aiforu.kr.
- 024042463
- 01032667931
- [email protected]
[추천]robots.txt 작성팁

| 목차 |
| 1. Disallow와 Allow 조합 2. 디렉토리명의 일부만 사용 3. 파일 확장자로 차단 4. 유효한 robots.txt URL의 예 5. 분석기 추천 : Yandex 웹마스터도구중 Robots.txt analysis(Robots.txt 분석) 6. User-agent 7. robots.txt 파일을 이용하여 검색엔진에 즉시 색인되게 하기 8. 기타 자주 묻는 질물(FAQ) |
웹마스터를 위한 검색 이야기(4) – robots.txt 작성팁 하나
아래의 초록색 글은 구글 한국블로그에 게시된 글입니다. 2017년 8월 현재는 삭제되었는데 좋은 사례여서 게제합니다.
작성일: 2011년 1월 7일 금요일
이하 초록색은 구글 한국 블로그에 있던 내용인돼 2021.1.22 현재는 해당 블로그에서는 삭제되었으나 내용이 훌륭하여 공유합니다. 안녕하세요, 구글코리아 소프트웨어 엔지니어 이동휘 입니다.
오 늘은 많은 웹사이트 담당자분들이 robots.txt(로봇제어파일)을 작성하면서 걱정하시는 문제를 짚어보려고 합니다. 때때로 대형 웹사이트 담당자분들이 robots.txt의 규칙과 내용을 비교적 잘 이해하고 있으면서도, 검색로봇이 접근하지 말아야 할 디렉토리의 목록을 robots.txt 에 입력하는 것이 오히려 악의적인 해커들에게 힌트를 주는 것이 아닌지 걱정을 하시거든요.

[제가 직접(!) 그려본 침입개념도입니다]
예를 들어, robots.txt 파일에 검색로봇을 차단할 디렉토리를 다음과 같이 지정한다고 가정합니다.
User-agent: *
Disallow: /admin
Disallow: /private_db
robots.txt 는 홈페이지처럼 공개되어 있는 파일이므로 악의적인 해커는 우선 robots.txt파일을 쭈욱 읽어본 다음 회심의 미소를 지으며 /admin이나 /private_db 폴더부터 우선 공격한다는 이야기지요. (로봇제어파일의 소개는 이전 포스트를 참고하세요.)
이에 대하여 완벽하지는 않지만 해결책을 알려드리겠습니다.
1. Disallow와 Allow 조합
모든 파일을 Disallow한 다음 공개할 디렉토리만 선택적으로 Allow하는 방법입니다. 이 방법은 Allow로 지정해야할 디렉토리가 많지 않을 때 유용합니다. 예를 들면 다음과 같습니다.
User-agent: *
Disallow: /
Allow: /index.html
Allow: /public
모든 검색로봇에 대해서 해당 사이트의 모든 파일을 차단(두번째 행)한 후, /index.html 파일과 /public 디렉토리를 허용한다는 뜻입니다. /public 디렉토리라고 했지만 사실 정확히 얘기하면 /public으로 시작하는 어떤 URL 경로도 허용합니다. 예를 들어, /public_db, /public/list.html 또는 /public?q=hello 도 모두 허용됩니다.
Disallow 관련 조언
- robots.txt에 ‘Disallow : /’을 가능하면 포함시키지 마세요. 이렇게 되면 모든 검색로봇의 접근을 차단합니다. 이것은 검색엔진측면에서는 절대 실수하지 말아야 할 기초적인 내용이지만 수많은 웹사이트에서 발견되곤 합니다.
- Disallow : /’는 구글 크롤링봇들의 웹사이트 접속을 차단시켜 크롤링 오류를 발생시키므로 구글 광고 비승인되게 하는 원인이 되기도 합니다.
네이버 관련 Disallow
아래는 네이버 포털, 네이버 쇼핑, 그리고 네이버 지도에 관한 robots.txt들입니다. 기본적으로 모든 ‘disallow : /’입니다. 경쟁자들이 네이버의 컨텐츠를 크롤링하는 것을 막기 위해 ‘disallow : /’한 것으로 판단됩니다. 그런데 https://shopping.naver.com/robots.txt 를 보시면 ‘disallow : /’와 ‘allow : /’가 모두 있습니다. 어쩌라는 것인지 이해가 안 됩니다. 이것이 국내 최고의 검색 포털이라고 하는 네이버의 robots.txt입니다. 하물며 다른 웹사이트나 쇼핑몰은 어떠할까요? 자만하지 마시고 자사/자신의 사이트가 검색엔진에 노출이 되고 있지 않다면 꼭 robots.txt를 살펴보시길 권합니다.
https://www.naver.com/robots.txt : 네이버
User-agent: *
Disallow: /
Allow : /$ https://shopping.naver.com/robots.txt
User-agent: *
Disallow: /
User-agent: Yeti
Disallow: /v1
Disallow: /my
Disallow: /*/*/store/
Disallow: /*/*/stores/
Disallow: /*/store/
Disallow: /*/stores/
Disallow: /*/brands/
Disallow: /outlink/storehome/
Disallow: /storehome/
Allow: /https://map.naver.com/robots.txt
User-agent: *
Disallow: /
Allow: /$
Allow: /p/$
Allow: /v5/$
Sitemap: https://map.naver.com/sitemap.xml2. 디렉토리명의 일부만 사용
두 번째로는 차단할 디렉토리명의 일부만을 사용하는 방법입니다. 위의 예에서도 보셨지만 Disallow나 Allow 항목의 디렉토리명은 사실은 URL경로의 앞쪽만 일치하면 적용됩니다. 예를 들면,
User-agent: *
Disallow: /a
Disallow: /p
이렇게만 적어도 /admin 디렉토리와 /private_db 디렉토리의 내용 모두 차단됩니다. 이때 주의할 것은, /public 디렉토리도 /p로 시작하므로 이럴 경우는 좀 더 자세히 적어주는 것이 좋습니다. 다음과 같이요.
Disallow: /pri
아니면, Allow: /public 을 따로 추가해주어도 되겠지요.
3. 파일 확장자로 차단
추가적으로 한가지 더 알려드리자면 파일의 확장자만을 기준으로 차단이나 허용이 가능합니다. 예를 들어, 우리 사이트의 모든 PHP프로그램은 검색로봇이 접근하지 않도록 하려면 다음과 같이 하면 됩니다.
User-agent: *
Disallow: /*.php
/public/program.php, /filename.php?q=hello 등의 .php 확장자를 가진 페이지로의 접근이 차단됩니다. 와일드카드 문자 ‘*’는 그 자리에 아무 문자가 없을 수도 있고 임의의 어떤 문자열이 올 수도 있습니다.
robots.txt는 정상적인 검색로봇과 웹마스터가 소통하는 창구일 뿐 개인정보 보호나 시스템 보안과는 연결고리가 크지 않습니다.
robots.txt를 제공하면 해커들의 공격을 받을 수 있다고 우려하시는 분들이 있는데 그렇지 않습니다. 해커를 얕잡아 보지 마십시오. 단지 robots.txt파일에 써 있는 내용을 통해 디렉토리명을 아는 정도로 위험해질 시스템이라면 robots.txt파일과 관계없이 이미 악의적 공격자의 먹이감이 될 수 있습니다. 컴퓨터 세계에서는 방어자보다 공격자가 훨씬 유리하며 보이지 않는 악의적 해커는 단순한 힌트 한 두개가 없다고 절대로 포기하지 않거든요.
4. 유효한 robots.txt URL의 예
구글검색센터의 Google에서 robots.txt 사양을 해석하는 방법 에 자세한 robots.txt URL의 예들이 있습니다.
여기에 옮기려하였으나 JSON 업데이트 실패가 계속 나와 올리지 못했습니다. 더 이상 시도하지 말아주세요.
5. 분석기 추천 : Yandex 웹마스터도구중 Robots.txt analysis(Robots.txt 분석)
[To KSH memp]”6. 분석기 추천 : Yandex 웹마스터도구중 Robots.txt analysis(Robots.txt 분석)” 내용중 수정 변경하는 내용이 있으면 아래의 게시글에 해당부분도 똑같이 수정 변경해 주세요.
얀덱스 웹마스터 도구( https://webmaster.yandex.com/ )
사용법
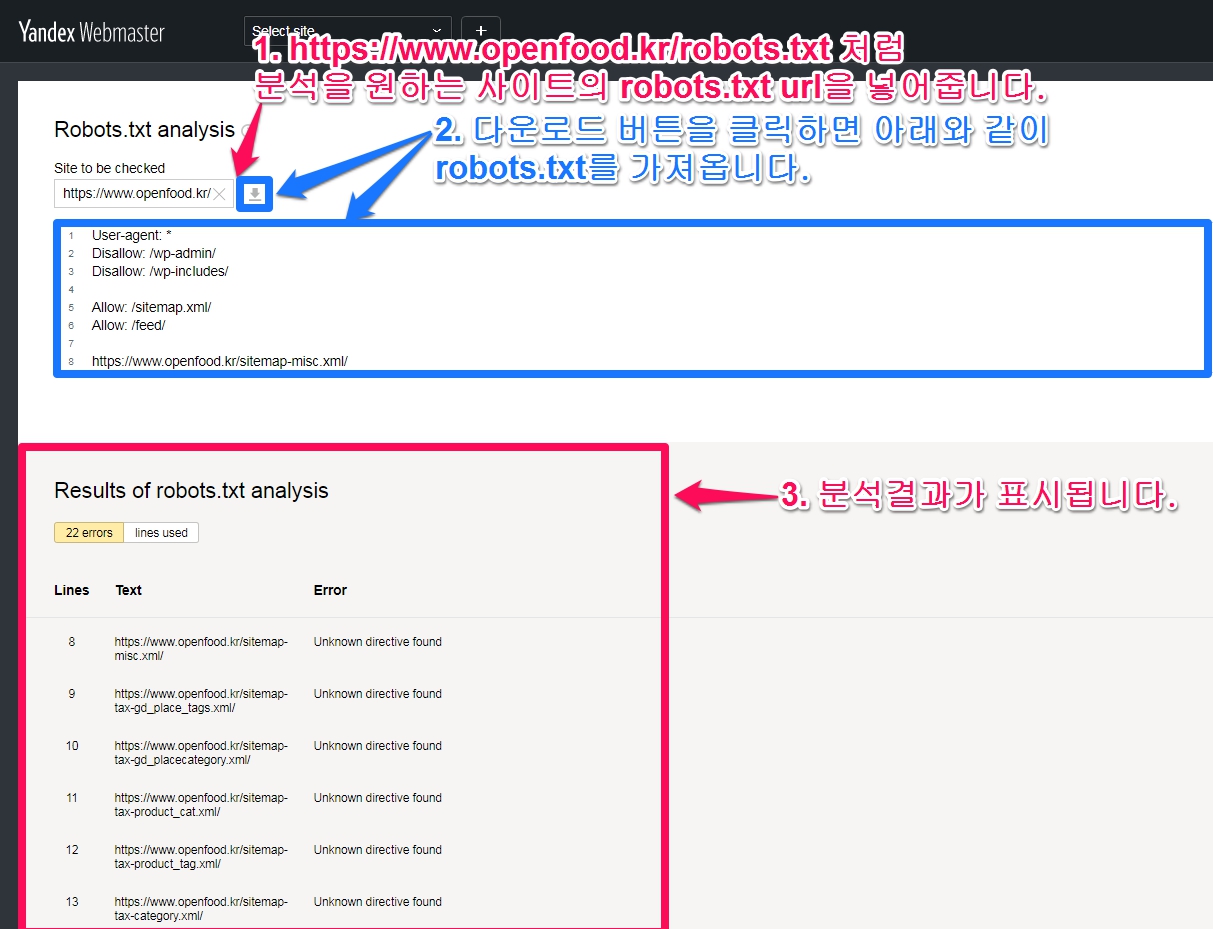
- 검사할 필드에 robots.txt 의 웹 사이트의 주소를 입력합니다. 예 : https://example.com/robots.txt. 소유권을 주장하지 않은 모든 웹사이트의 robots.txt를 검증할 수 있으므로 꼭 활용하세요.
-
 아이콘을 클릭하십시오 .
아이콘을 클릭하십시오 . - robots.txt 의 내용과 분석 결과는 아래와 보여집니다.
아래의 이미지에는 에러의 내용으로 ‘Unknown directive found(알 수없는 지시문이 발견되었습니다)’ 이 보입니다.
Sitemap: https://www.copy114.kr/sitemap.xml
와 같이 지시문을 작성해 주어야 하는데 아래와 같이 “Sitemap : “을 빼먹은 경우입니다.
‘Sitemap:’의 S는 대문자로 시작되어야 합니다. https://www.copy114.kr/sitemap.xml 뒤에 ‘/’가 붙지 말아야 합니다./가 붙이면 파일로 인식하지 않고 url 경로로 인식합니다.
https://www.copy114.kr/sitemap.xml
Robots.txt errors 상세 설명
오류(Errors)
robots.txt 파일을 파싱 할 때 발생하는 오류 목록입니다 .(List of errors when parsing the robots.txt file.)
| 오류(Error) | Yandex 확장(Yandex extension) | 상세 설명( Description ) |
|---|---|---|
| 규칙이 / 또는 *로 시작하지 않습니다. (Rule doesn’t start with / or *) | 예(Yes) | 규칙은 / 또는 * 문자로만 시작할 수 있습니다.(A rule can start only with the / or * character.) |
| 여러 ‘User-agent : *’규칙이 발견됨 (Multiple ‘User-agent: *’ rules found) | 아니요(No) | 이 유형의 규칙은 하나만 허용됩니다.(Only one rule of this type is allowed.) |
| Robots.txt 파일 크기 제한 초과 (Robots.txt file size limit exceeded) | 예(Yes) | 파일의 규칙 수가 2048 개를 초과합니다.(The number of rules in the file exceeds 2048.) |
| 규칙 앞에 사용자 에이전트 지시문이 없습니다.(No User-agent directive in front of rule.) | 아니요(No) | 규칙은 항상 User-agent 지시문을 따라야합니다. 아마도 파일에 User-agent 뒤에 빈 줄이있을 수 있습니다.(A rule should always follow the User-agent directive. Perhaps, the file contains an empty line after User-agent.) |
| 규칙이 너무 깁니다.(Rule is too long) | 예(Yes) | 규칙이 길이 제한 (1024 자)을 초과합니다.(The rule exceeds the length limit (1024 characters).) |
| 잘못된 Sitemap 파일 URL 형식 (Invalid Sitemap file URL format) | 예(Yes) | 사이트 맵 파일의 URL은 프로토콜을 포함, 전체에 지정해야합니다. 예 : https://www.example.com/sitemap.xml(The Sitemap file URL should be specified in full, including the protocol. For example, https://www.example.com/sitemap.xml)예 : 아래와 같이 지시문(Sitemap)을 잘못하여 2번 작성하는 경우에도 이 에러가 보여집니다.Sitemap: Sitemap: https://www.openfood.kr/sitemap-archives.xml/ |
| 잘못된 Clean-param 지시문 형식 (Invalid Clean-param directive format ) | 예(Yes) | Clean-param 지시문은 로봇이 무시하는 하나 이상의 매개 변수와 경로 접두사를 포함해야합니다. 매개 변수는 & 문자로 구분됩니다. 공백으로 경로 접두어와 구분됩니다.( The Clean-param directive should contain one or more parameters ignored by the robot, and the path prefix. Parameters are separated with the & character. They are separated from the path prefix with a space. ) |
경고(Warnings)
robots.txt 파일을 파싱 할 때 발생하는 경고 목록입니다 .(List of warnings when parsing the robots.txt file.)
| 경고(Warning) | Yandex 확장(Yandex extension) | 상세 설명(Description) |
|---|---|---|
| 불법 문자가 사용되었을 가능성이 있습니다.(It’s possible that an illegal character was used) | 예(Yes) | 파일에 * 및 $ 이외의 특수 문자가 있습니다.(The file contains a special character other than * and $.) |
| 알 수없는 지시문이 발견되었습니다.(Unknown directive found) | 예(Yes) | 파일에 robots.txt 사용 규칙에 설명되지 않은 지시문이 있습니다 . 이 지시문은 yandex 외에 다른 검색 엔진의 로봇에서 사용할 수 있습니다. robots.txt 사용 규칙 을 참조하시면 robots.txt 에서 사용할 수 있는 지시문과 어떤 경우에 사용하는지 자세히 알 수 있습니다.(The file contains a directive that isn’t described in the rules for using robots.txt. This directive may be used by the robots of other search engines)예 :Sitemap: https://www.copy114.kr/sitemap.xml와 같이 지시문을 작성해 주어야 하는데 아래와 같이 “Sitemap : “을 빼먹은 경우가 그 예입니다.https://www.copy114.kr/sitemap.xml |
| 구문 오류(Syntax error) | 예(Yes) | 문자열은 robots.txt 명령어 로 해석 될 수 없습니다.( The string cannot be interpreted as a robots.txt directive. ) |
| 알수없는 오류(Unknown error) | 예(Yes) | 파일을 분석하는 동안 알 수없는 오류가 발생했습니다. 지원 서비스에 문의하십시오.(An unknown error occurred while analyzing the file. Contact the support service.) |
URL 유효성 검사 오류(URL validation errors)
Robots.txt 분석 도구 의 URL 유효성 검사 오류 목록입니다.(The list of the URL validation errors in the Robots.txt analysis tool.)
| 오류(Error) | 상세 설명(Description) |
|---|---|
| 구문 오류(Syntax error) | URL 구문 오류입니다.(URL syntax error.) |
| 이 URL은 도메인에 속하지 않습니다. (This URL does not belong to your domain) | 지정된 URL이 파일이 구문 분석되는 사이트에 속하지 않습니다. 사이트 미러의 주소를 입력했거나 도메인 이름을 잘못 입력했을 수 있습니다.(The specified URL does not belong to the site for which the file is parsed. Perhaps you entered the address of a site mirror or misspelled the domain name.) |
Yandex에서 권장하는 robots.txt 지시문(명령문)들
| 지시문(명령문, Directive) | 그것이하는 일(What it does) |
|---|---|
| User-agent *(사용자 에이전트 *) | robots.txt에 나열된 규칙이 적용 되는 로봇을 나타냅니다.(Indicates the robot to which the rules listed in robots.txt apply.) |
| Disallow(금지) | 사이트 섹션 또는 개별 페이지 인덱싱을 금지합니다.(Prohibits indexing site sections or individual pages.) |
| Sitemap(사이트 맵) | 사이트에 게시된 Sitemap 파일 의 경로를 지정합니다 .( Specifies the path to the Sitemap file that is posted on the site. ) |
| Clean-param(깨끗한 매개 변수) | 페이지 URL에 색인 생성시 무시해야하는 매개 변수 (예 : UTM 태그)가 포함되어 있음을 로봇에 알립니다. (Indicates to the robot that the page URL contains parameters (like UTM tags) that should be ignored when indexing it.)URL에 UTM 매개 변수가 있는 경우 이것을 제외한 URL이 색인되게 하라는 의미인데 별 실익은 없어 보입니다. |
| Allow(허용) | 사이트 섹션 또는 개별 페이지 인덱싱을 허용합니다.(Allows indexing site sections or individual pages.) |
| Crawl-delay(크롤링 지연) | 검색 로봇이 한 페이지를로드 한 후 다른 페이지를로드하기 전에 대기하는 최소 간격 (초)을 지정합니다.(Specifies the minimum interval (in seconds) for the search robot to wait after loading one page, before starting to load another.)지시문 대신 Yandex.Webmaster 의 크롤링 속도 설정 을 사용하는 것이 좋습니다 .(We recommend using the crawl speed setting in Yandex.Webmaster instead of the directive.)크롤링 대기 시간을 설정하면 다운로드가 늘이 페이지들의 색인이 안되는 문제를 해결할 수 있습니다. |
* 필수 지시문(명령문).
Disallow, Sitemap 및 Clean-param 지시문이 가장 자주 사용되고 필요합니다.
예를 들면 :
User-agent: * # specify the robots that the directives are set for
Disallow: /bin/ # prohibits links from the Shopping Cart.
Disallow: /search/ # prohibits page links of the search embedded on the site
Disallow: /admin/ # prohibits links from the admin panel
Sitemap: http://example.com/sitemap # specify the path to the site's sitemap file for the robot
Clean-param: ref /some_dir/get_book.pl6. User-agent
User-agent 는 제어할 로봇의 User-Agent를 적어줍니다.
예를들면, 아래와 같이 설정할 수 있습니다.
(예) 네이버 검색로봇만 접근 가능하게 설정. 네이버 검색로봇의 이름(User-Agent)은 Yeti 입니다.
User-agent: Yeti
Allow: /
(예) 모든 검색엔진의 로봇에 대하여 접근 가능하게 설정
User-agent: *
Allow: /아래와 같이 설정하는 것이 너무도 당연한데 사이트들을 살펴보다 보면 User-agent: Yeti(네이버검색로봇만 접근허용합니다.) 로 해 놓은 경우도 있고, Disallow: /(검색엔진은 루트 디렉토리를 포함한 모든 디렉토리를 크롤링 색인하지 마세요)로 해놓은 경우도 있습니다. 국정원이 아닌이상 상업용 사이트에서 Disallow: 를 설정하는 것은 검색엔진최적화(SEO)에 측면에서는 상상할 수 없는 치명적은 실수입니다.
(예) 모든 검색엔진의 로봇에 대하여 접근 가능하게 설정
User-agent: *
Allow: /유명한 로봇들[편집]
http://user-agent-string.info/list-of-ua/bots
| 이름 | User-Agent |
| Googlebot | |
| Google image | Googlebot-image |
| Msn | MSNBot |
| Naver | Yeti( 2005년 이전에는 NaverBot.) |
| Daum | Daumoa |
크롤러중 검색엔진bot으로는 2005년 이전에는 NaverBot을 대체한 네이버의 Yeti, 다음의 Daumoa bot이 보입니다.( udger.com 는 User Agents Analysis 사이트입니다. )
크롤러중 검색엔진bot들
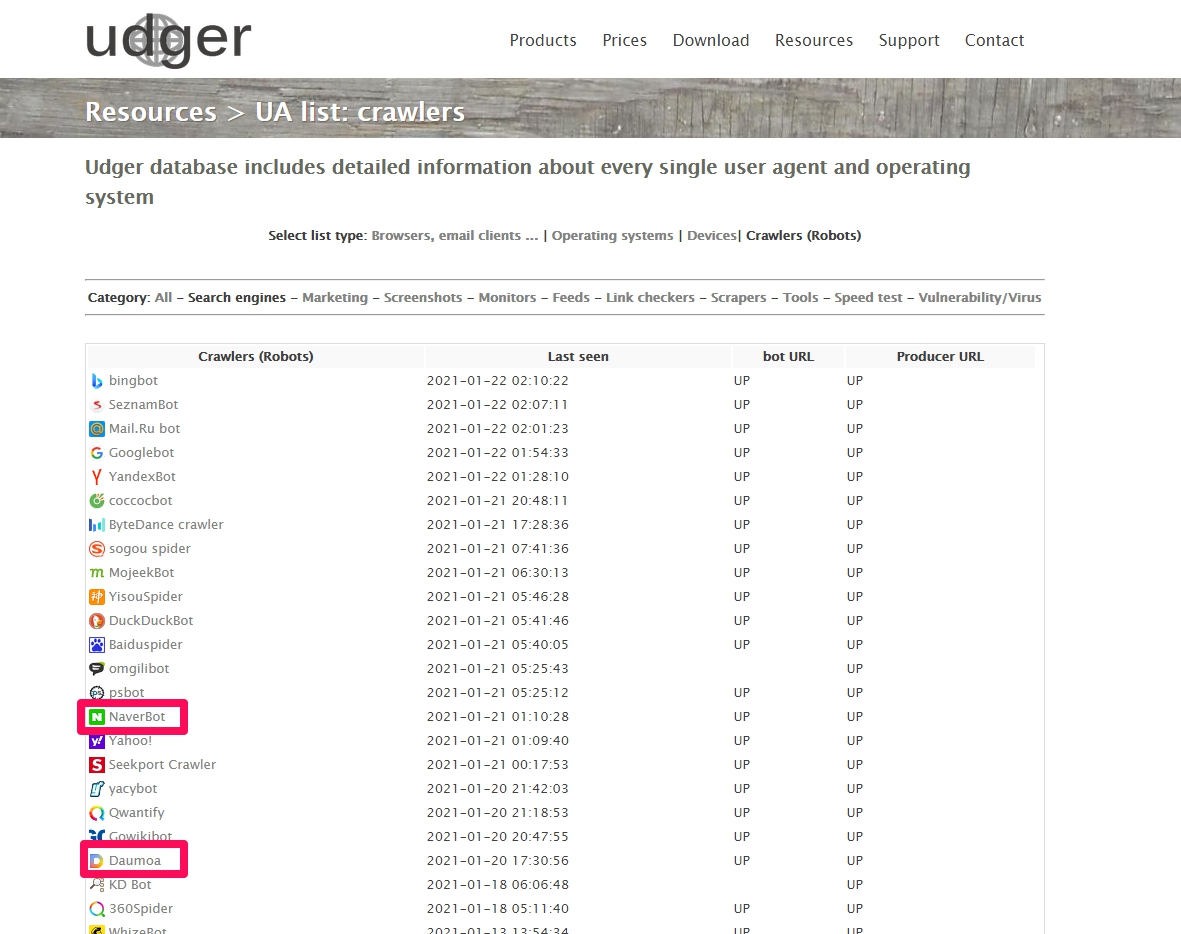
모든 크롤러들에게 크롤링(색인)되게 한다는 것은 검색엔진최적화에서 매우 중요한 의미가 있습니다. http://user-agent-string.info/list-of-ua/bots 에는 셀 수 없이 많은 전세계 크롤러들이 있는데 이들이 모두 그러하지는 않지만 많은 크롤러들의 목적은 색인후 자사 사이트에 검색결과로 보여주는 경우가 많습니다. 이들 크롤러들은 평판이 높은 양질의 사이트들입니다.(네이버가 이들 크롤러들중 하나인 것을 감안하면 쉽게 이해가 되실 것입니다. 이들 크롤러들은 특정 국가의 검색포탈인 경우가 많습니다.) 이들 사이트에 자사/자신의 사이트가 노출된다는 것은 고품질 백링크를 얻는 것을 의미하므로 검색엔진최적화에 있어 매우 중요한 의미를 가집니다.
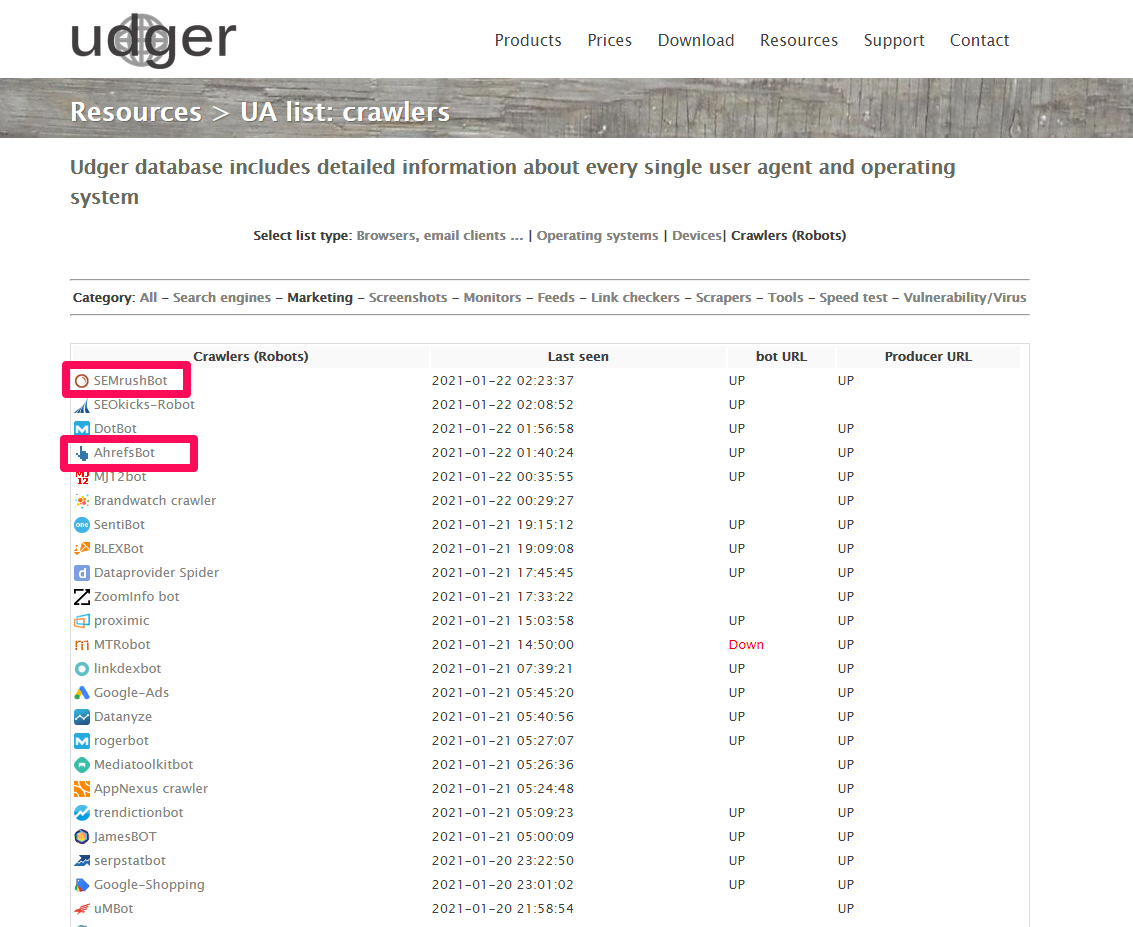
크롤러중 Marketing bot들
크롤러중 Marketing bot들로는 저에게는 친숙한 SEMrushBot, MOZ(DotBot 는 MOZ의 크롤러입니다.Rogerbot 은 Moz’s Campaign Crawler 입니다.), AhrefsBot 을 확인할 수 있었습니다. 자사/자신이 이용하는 마케팅 솔루션이 자주 크롤링을 하여 최신 데이터를 반영하는지 판단하고자 할때 여기서 확인해 보면 좋을 것 같습니다.
재미삼아 SEOkicks-Robot 를 알아보았습니다. SEOkicks-Robot 는 백링크 검사기입니다. 이것은 백링크는 구글애널리틱스로도 충분히 확인할 수 있으므로 특별한 필요하지는 않을 것 같습니다.
SEOkicks는 독일에 기반을 둔 백 링크 검사기입니다. 웹 사이트에 따르면 가장 자주 사용되는 백 링크 데이터베이스 중 하나입니다.
자체 크롤러를 사용하여 SEOkicks는 웹 사이트를 통해 제공되는 링크 데이터를 수집합니다.
링크 확인을 위해 웹 사이트 주소를 입력하면 다음 목록이 제공됩니다.
- Referring domains( 참조 도메인 )
- Referring pages( 참조 페이지 )
- Top pages( 톱 페이지 )
- Status codes( 상태 코드 )
- Anchor text( 앵커 텍스트 )
- Reverse IP( 역방향 IP ? )
크롤러중 tool bot들
Wappalyzer 는 의아하게 tool bot으로 분류되어 있습니다.
7. robots.txt 파일을 이용하여 검색엔진에 즉시 색인되게 하기
중요 : robots.txt 파일에서 사이트 맵의 위치를 잘 알려주면 웹마스터 도구들에서 웹페이지를 수동색인 요청하는 것보다 비교할 수 없을 정도로 효율적이니 꼭 활용하세요.
robots.txt 파일을 사용하여 사이트내에 사이트 맵 파일이 어디에 설치되어 있는지를 검색 엔진에 알게 할 수 있습니다. 검색 엔진이 사이트에 액세스하는 경우, robots.txt 파일이 존재하면 가장 먼저 robots.txt를 살펴봅니다. 이때 사이트 맵 장소가 기재되어 있으면 사이트 맵을 읽어들입니다.
웹 마스터 도구를 이용해 직접 Google에 사이트 맵을 보낼 수 있지만 검색 엔진은 Google뿐만이 아니기 때문에 robots.txt를 사용하여 사이트 맵의 위치를 알려주는 것이 중요합니다.
robots.txt에 사이트 맵의 위치를 알려주려면 다음과 같이 적어주세요. (파일 이름은 작성자 임의의 파일 이름을 지정하십시오).
Sitemap : http://www.example.com/sitmap.xml
- 기술 위치(내용을 적은 위치)는 robots.txt 중이면 어디라도 상관 없습니다. 파일의 맨 위에 두어도 괜찮습니다.
8. 기타
네이버의 robots.txt
네이버 웹마스터도구에서 [검증] -> [robots.txt] 에서 네이버가 robots.txt 를 잘 읽고 색인하는지 확인하세요.
네이버에 관해서는 사이트에 robots.txt 를 루트 디렉토리에 올려놓았다고 하여 robots.txt 가 잘 작동할 것이라고 안주하고 간과하지 말라는 것입니다. 꼭 robots.txt를 검증하는 것을 생략하지 말아주세요.
2021-01-22 기준 최근에 제가 운영하는 새로운 쇼핑몰 사이트의 모든 페이지들을 웹페이지 수집 요청을 하였는데, 색인이 안되는 문제를 해결하느냐고 고금 분투하던중 발견한 것인데 네이버가 robots.txt를 수집하지않아 빈칸으로 남아 있었습니다.
네이버 웹마스터 도구에 대한 보다 상세한 정보를 원하시는 분은 아래의 게시글을 참조하세요.
구글의 robots.txt
구글의 robots.txt 의 url 은 https://www.google.com/robots.txt 입니다. 구글은 어떤 부분은 접근을 허락하고 어떤 부분은 접근을 허락하지 않는지 볼 수 있습니다.
자주 묻는 질문(FAQ)
내 웹사이트에 robots.txt 파일이 필요한가요?
아니요 이기도 하고 예 이기도 합니다.
아니요. 경험상으로는 잘못된 robots.txt(대표적인 경우, Disallow)가 색인을 막는 경우를 많이 보았습니다.
Googlebot에서 웹사이트를 방문하면 먼저 robots.txt 파일 검색을 시도하여 크롤링하기 위한 권한을 요청합니다. robots.txt 파일, robots meta 태그 또는 X-Robots-Tag HTTP 헤더가 없는 웹사이트는 일반적으로 정상적으로 크롤링되고 색인이 생성됩니다.
예. 잘 작성된 사이트맵을 포함하는 robots.txt는 색인이 매우 유용합니다.
robots.txt 파일을 만들려면 어떤 프로그램을 사용해야 하나요?
유효한 텍스트 파일을 만드는 프로그램이면 무엇이든 사용할 수 있습니다.
robots.txt 파일을 만드는 데 사용되는 일반적인 프로그램에는 Notepad, TextEdit, vi 또는 emacs가 있습니다.
파일을 만든 후 robots.txt 테스터로 유효성을 검사하세요.
robots.txt 파일의 변경사항이 검색결과에 반영되는 데 얼마나 오래 걸리나요?
먼저 robots.txt 파일의 캐시를 새로고침해야 합니다. Google은 일반적으로 최대 하루 분량의 콘텐츠를 캐시합니다.
업데이트된 robots.txt를 Google에 제출하여 이 프로세스의 속도를 높일 수 있습니다.
변경사항을 발견한 후에도 크롤링 및 색인 생성은 복잡한 과정이기 때문에 때로는 개별 URL을 처리하는 데 시간이 걸릴 수도 있으므로 정확한 일정을 알려 드릴 수는 없습니다.
여러 웹사이트에서 같은 robots.txt를 사용합니다. 상대 경로 대신 전체 URL을 사용할 수 있나요?
아니요. robots.txt 파일의 규칙(sitemap: 제외)에는 상대 경로만 사용할 수 있습니다.
robots.txt 파일을 하위 디렉터리에 넣을 수 있나요?
아니요. robots.txt 파일은 웹사이트의 최상위 디렉토리에 넣어야 합니다.
비공개 폴더를 차단하고 싶습니다. 다른 사용자가 내 robots.txt 파일을 읽지 못하게 할 수 있나요?
아니요. robots.txt 파일은 다양한 사용자가 읽을 수 있습니다.
콘텐츠의 폴더나 파일 이름이 공개되지 않아야 하는 경우 robots.txt 파일에 나열하지 마세요.
사용자 에이전트 또는 다른 속성을 기반으로 여러 robots.txt 파일을 게재하는 것은 좋지 않습니다.
크롤링을 허용하려면 allow 규칙을 포함해야 하나요?
아니요. 구글의 경우, allow 규칙을 포함할 필요는 없습니다. 모든 URL은 암시적으로 허용되며 allow 규칙은 같은 robots.txt 파일에서 disallow 규칙을 재정의하는 데 사용됩니다.
참고자료 : 1. robots.txt 파일에서 사이트 맵의 위치를 지정하는 방법(no4)
2.나무위키의 robots.txt
3. 구글검색센터의 Google에서 robots.txt 사양을 해석하는 방법



1 Comment
[…] https://aiforu.kr/robots-txt-%ec%9e%91%ec%84%b1%ed%8c%81/ […]